最近发现在调用Gemini 2.5 Pro时,发现模型思考占用的token数超过了输出的token,思考功能如何关闭呢?或者如何去减少模型思考所消耗的token?
从官方文档来看:

那么如何降低思考所消耗的token呢?
Gemini API 还提供了以下参数:
temperature=0.1, # 控制随机性
max_output_tokens=500, # 限制输出长度
top_p=0.8, # 控制采样范围
top_k=40, # 限制候选词
candidate_count=1 # 生成候选数量
让我们去尝试修改参数来减少思考过程所消耗的token,最终对比结果!
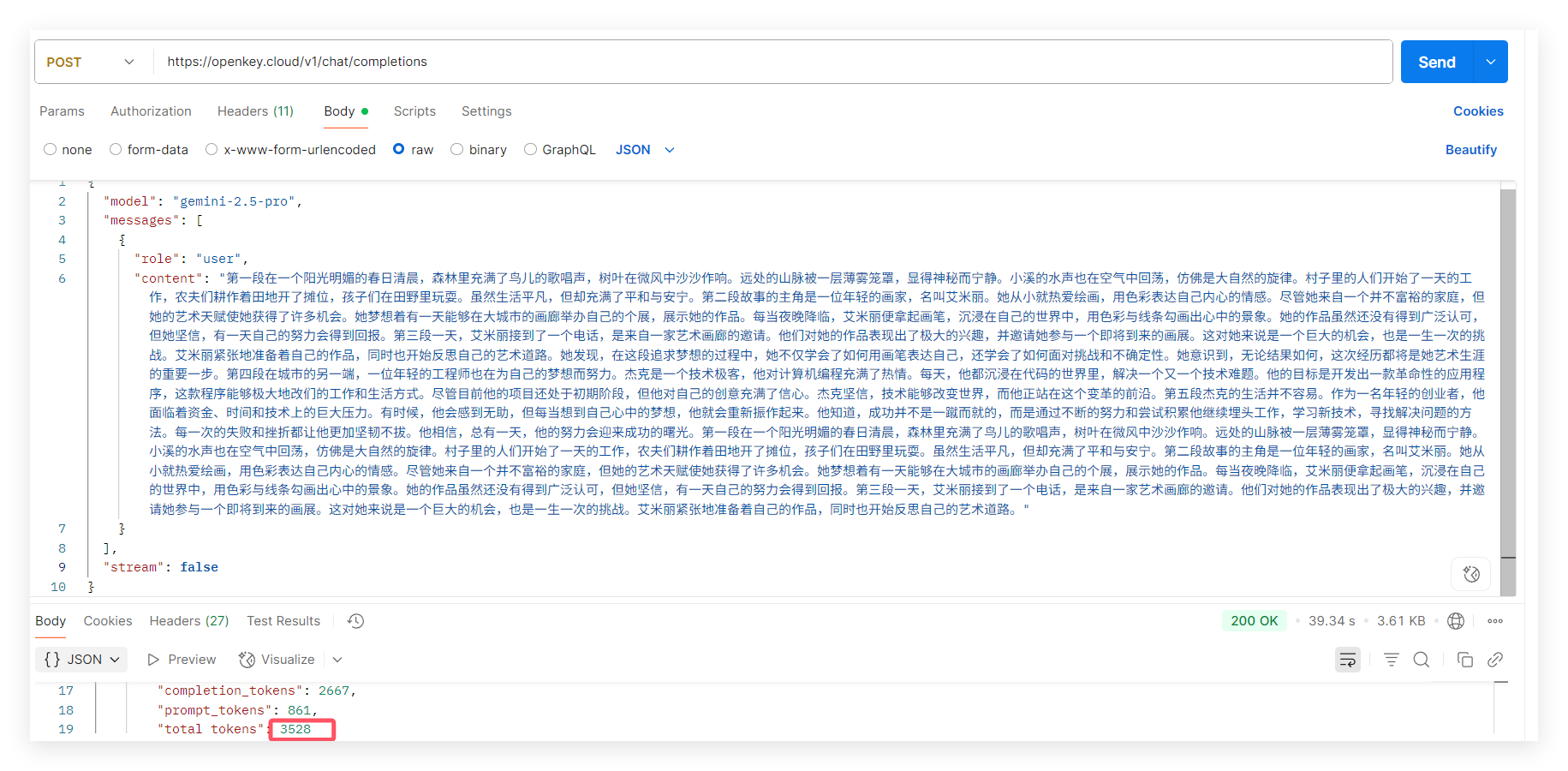
这是一个使用默认参数的原始请求:
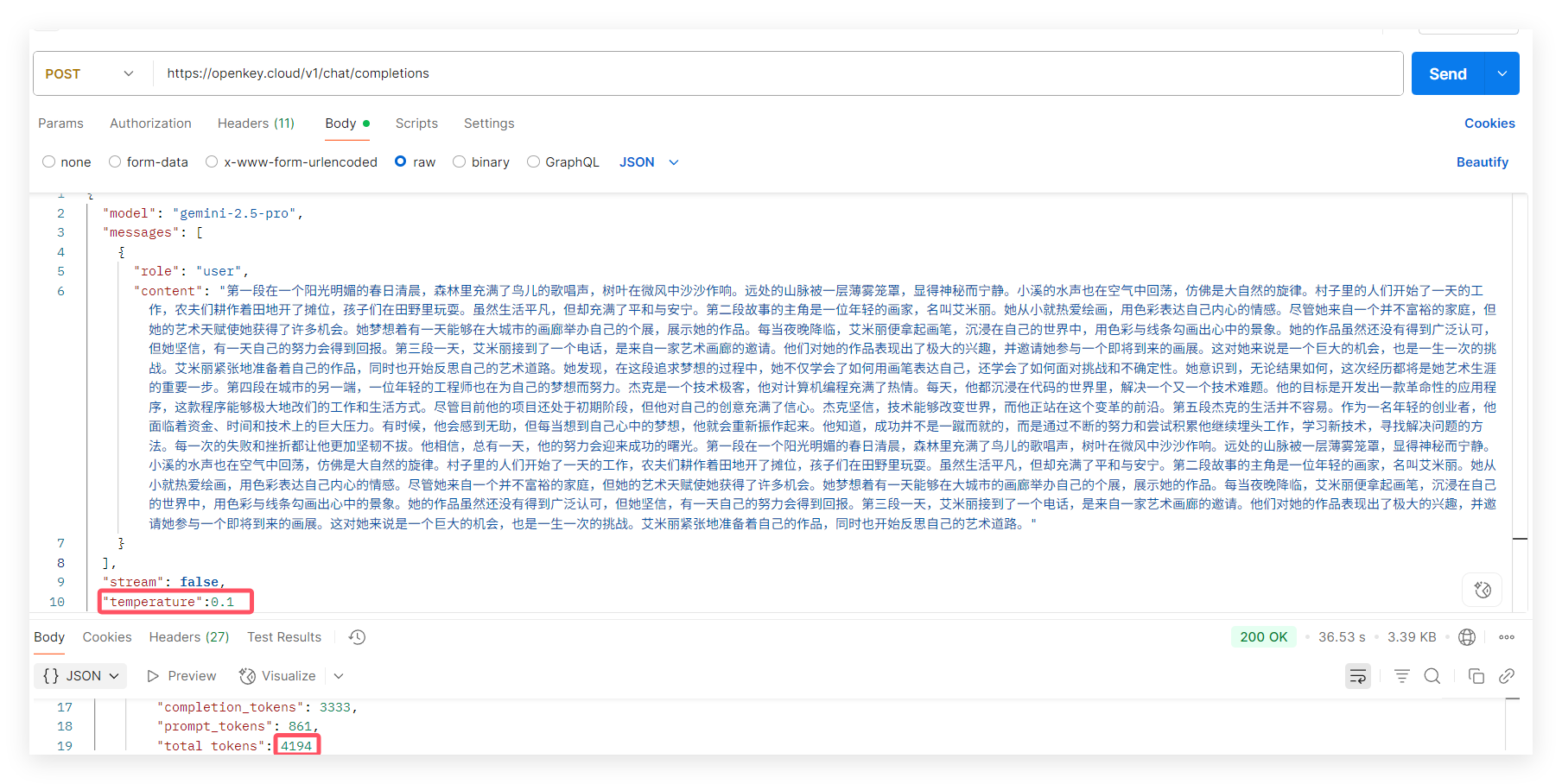
让我们来尝试优化参数,修改temperature=0.1时:
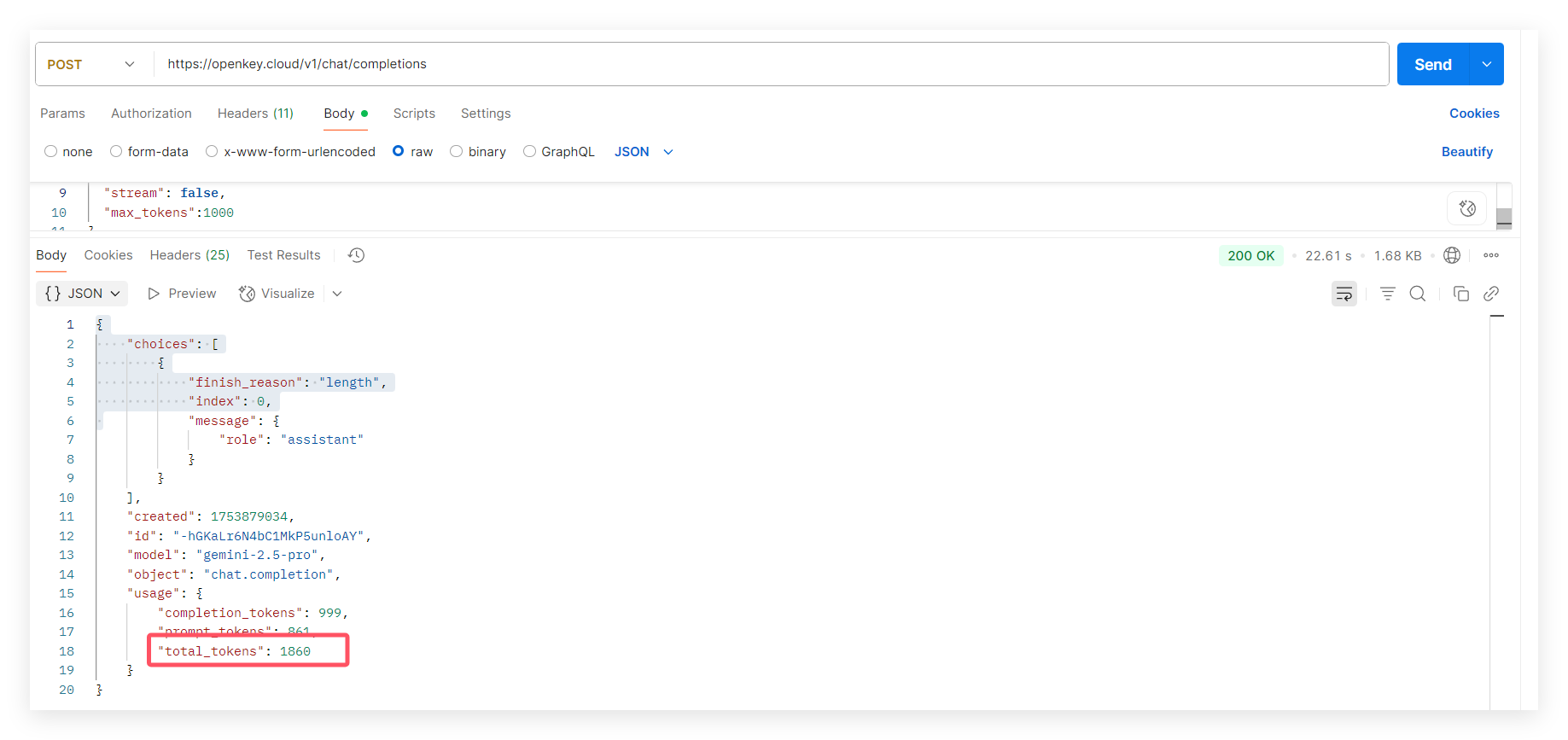
当限制max_tokens=1000时:
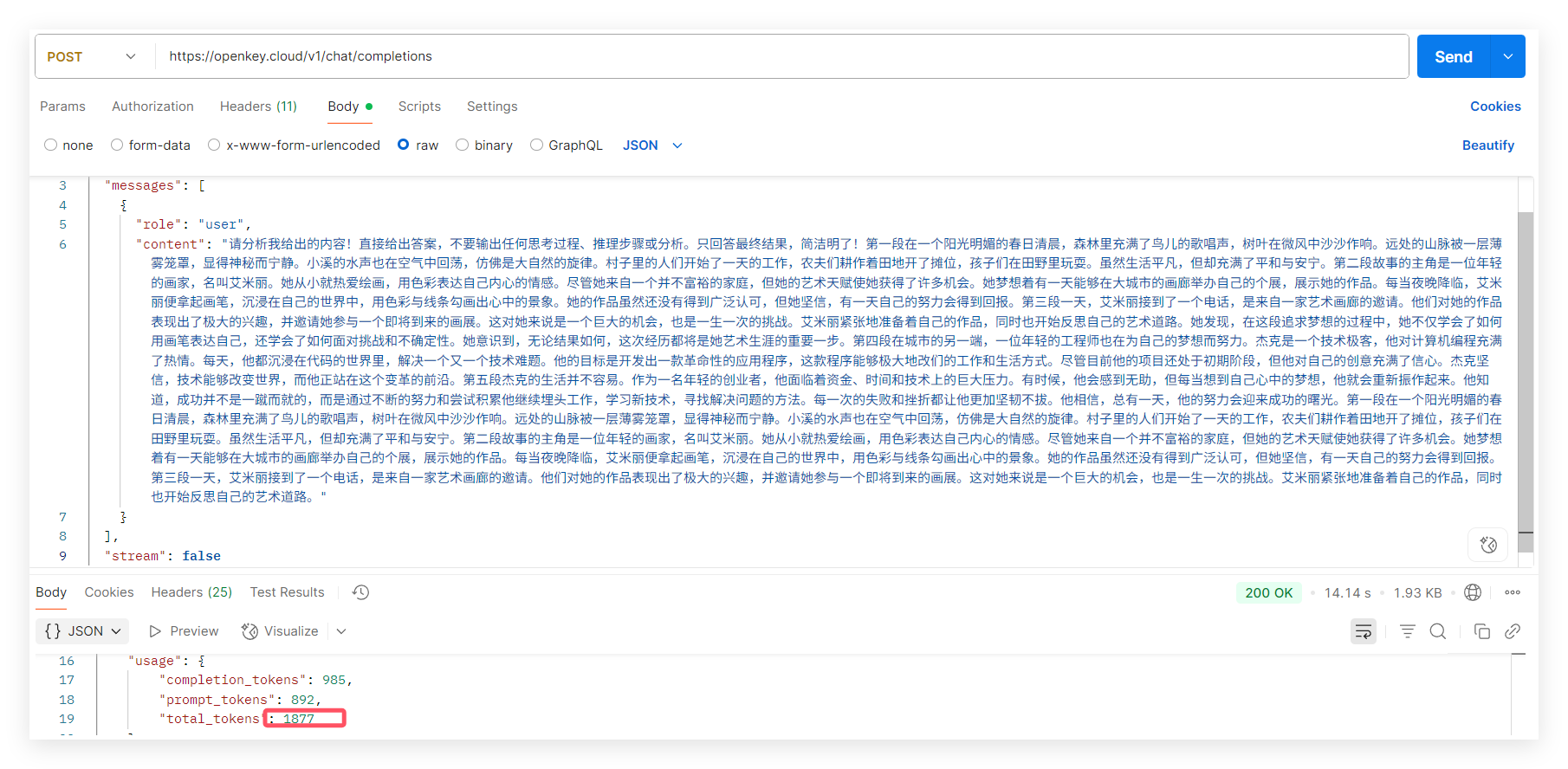
当尝试使用提示词去控制时:
例如:请直接给出答案,不要输出任何思考过程、推理步骤或分析。只回答最终结果,简洁明了
对比总结:
1、使用temperature参数(无效) 控制随机值为0.1时,token未减少反而增加,这里推测低 temperature(0.1)更详细、更完整,但可能包含更多思考过程;而高 temperature(0.7+):更简洁、更直接,可能节省 token
2、限制max_tokens数量(有效但是可能无结果返回),可以直接控制token消耗到一定范围,但是可能会出现上述图片中的结果,由于限制了token,模型还在思考过程中就中断了请求,导致没有结果返回
3、使用提示词控制(最有效),直接减少了一大半的token消耗
注意:以上测试仅为简单测试,如需效果最佳可配置更多的组合自行测试